Data and Machine Learning

Tian Zhang

After earned my bachelor degree, I applied to University of Southern California (USC) to continue my master study. Here, I learned a lot about the Statistic and Probability and their state of art usage, with a fancy name -- "Machine Learning", I also found that, compared to build robots, machine learning, with it's broad usage, are accually more easier to improved people's live, without cost a lot of money on choose and design best hardware to assemble a robot, all you need is just a computer, with your strong knowledge and sparking ideas!
I explored projects included statistic models to solve numerical classification and regression problems and applying deep learning to solve computer vision and natural language processing problems. I'm confident with working on heavily imbalanced dataset or selecting useful information from large dataset, using SVM, Random Forest, XGBoost, clustering to make classification and regression as well as used TensorFlow to implement CNN and RNN model to solve image classification and natural language processing problem.
I have a broad interested in Machine learning area, I'd like to use data to solve real world problem. Understand a real world problem and convert it into problem can be solve by using data I can get, which I call this process 'data language', than design and build a efficient model finally deploy it to real use and benefit people, these whole processes give me much fine!


This is my Intern project at AiTmed, a Telemedical startup head to Anaheim.
This project is aimed to deploy an image classification platform on amazon web service that can let customers train it's own model without deep learning knowledge. To work on that, I built a MobileNet model, the model was trained by images customer provided and stored in AWS S3. Model was also stored in Amazon S3 bucket. Customers can continue training the model anytime with new image and test performance by simply input APIs. And they also can classify new images based on their own model
What I did include design a simple MobileNet CNN model and design APIs that work on implement this model, extract features from image data customer loaded, load and save model from AWS S3, show model performance, build Docker container for this application to be easier deployment
This is a Image procesing project, aimed to build a convolution nerual network model to generate high resolution human face image based on lower resolutoin one in fast speed. when generating speed goes really fast, say 50 images per seconds, It can be applied to many areas, such as criminal face recognition in camera video, or live streaming quality improvement.
This project was based on a published paper (FSRCNN), mentioned a CNN model to create high resolution image. I improved the algorithm from this paper and built my own models, witch maintain the same performance and increase the image generation speed by 30% by change the model into mobileNet and shirk nearly 50% of parameters, also the original paper was focus on general image and my model focus specifically in human face


In this project, a human emotion recognition system was built by deep learning. (VGG-16 convolution neural network model) Model was trained by 12,993 images of human faces with eight basic emotions. (anger, fear, happiness, disgust, neutral, surprise, contempt, sadness)
I finished the following works:
1. Preprocessed and balanced data: upload image data and transfer into a data matrix, flip image upside down and make right/left rotate to expand training set. Separated data in different groups to overcome data imbalance.
2. Built deep learning model used Keras with Tensorflow framework: Built a VGG-16 ConvNet, trained in AWS E2 and saved parameters
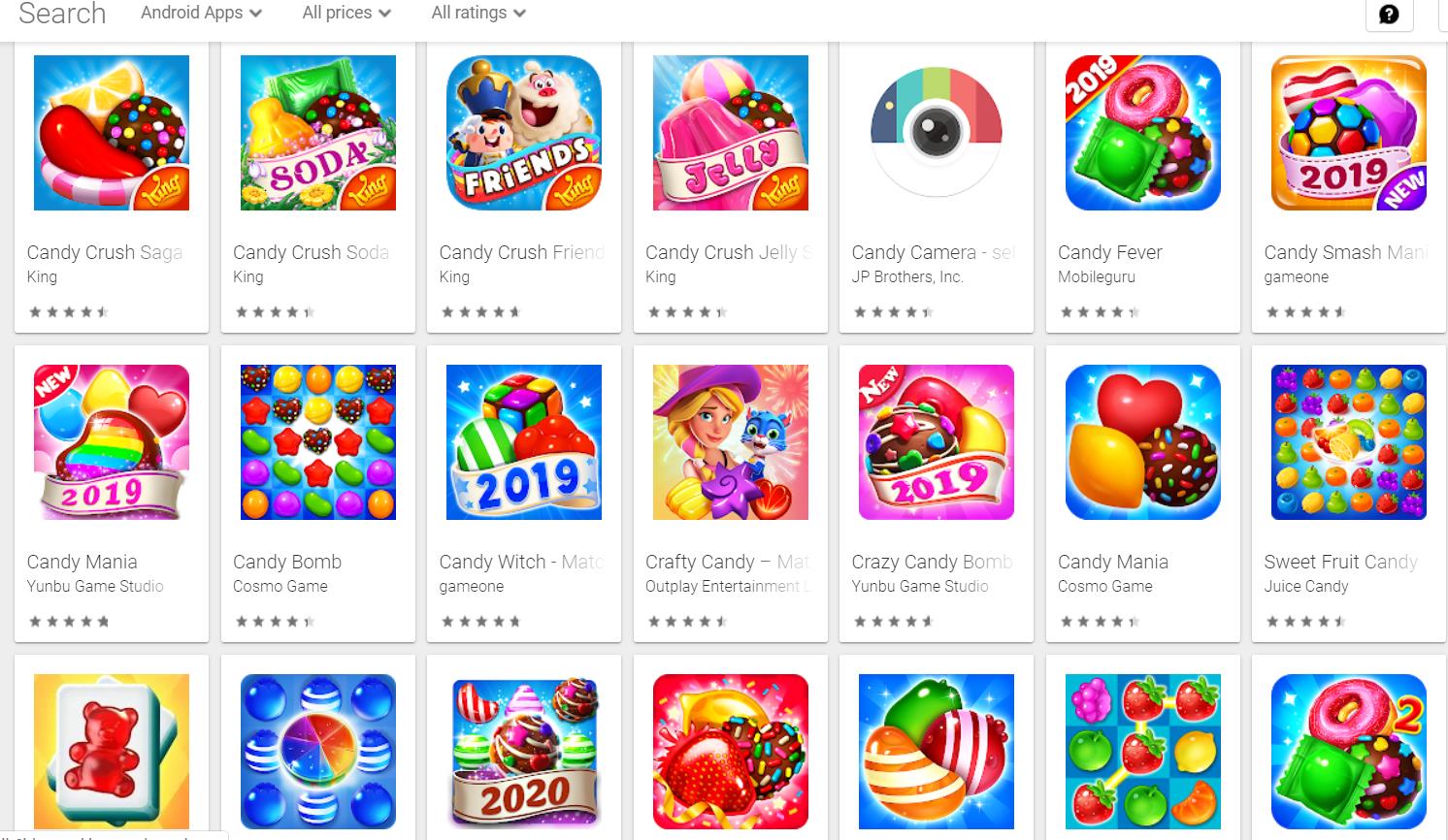
This project aimed to detect all copycat Apps in Google Play App store by the strength of unsupervised learning.
I extracted more than 40,000 Apps information include App description and resealse date and version, download, price,etc from Google Play App Store, and vectorize each App's description based on bag of words model, applies TF/IDF and PCA to reduce demension (reduce 90%), and clustering the final phrase vector by cosine similarity.
Though this method is simple, the final result is good. Take CANDY CRUSH as an example, In the first 80 similar Apps of CANDY CRUSH, there are 58 Apps are copycat or has similar functions.
This project aimed to detect which language was spoken in the audio record.
In this priject, I had 60 audio records (10 min for each) which contains reading in English, Mandarin and Hindi. My job is training a deep learning model to recognize spoken language based on this 60 audio data. I implemented my model by the following step:
Segmentate each audio record into small blocks which contain 10 seconds of language spoken audio. This expand my dataset into 3,000 audio data
Used Python pakage LibROSA to extract fetures from audio. This pakage help me extract 64 features for each second using Mel-frequency cepstral coefficients (MFCCs)
Build Recurrent Nerual Network(RNN) model with 2 LSTM layers to predict which language the test audio belong to. The model obtained an accuracy of 73.5%


This project aimed to build a regression system to predict movie revenue from TMBD 5,000 movies dataset. So it could be used to predict if a new released movie with make profit or not.
To finish this project, a few works were done by myself:
1. Applied PCA to extract important feature, applied semi-supervised 1NN to fill missing data.
2.Trained supervised machine learning models by random forest, output the DNN model as the best prediction model with an average error of less than 15%.
3. Applied KNN to find the first n nearest movie as the recommended relatively movie.
This is a course final project, me and my partner in charged of a News Popularity prediction model
The project aimed to predict how many people will likely to read a specific type of news based on news' field, published time, number of images, position in the newspaper or website, etc.

Use Matplotlib and Tableau to visualize data
Clean Data, generate data if not enough
Preprocess data by transfering words to numerical data, extracting most influenced features
Use MySQL and Spark to make query